
Google Earth Engine allows the analysis of all common, freely available satellite data on a cloud-based platform. This powerful tool is operated using Java programming. Once the code has been developed, it is executed within a few minutes! This means that analyses can be carried out in a short time that would take hours or days on conventional computers.
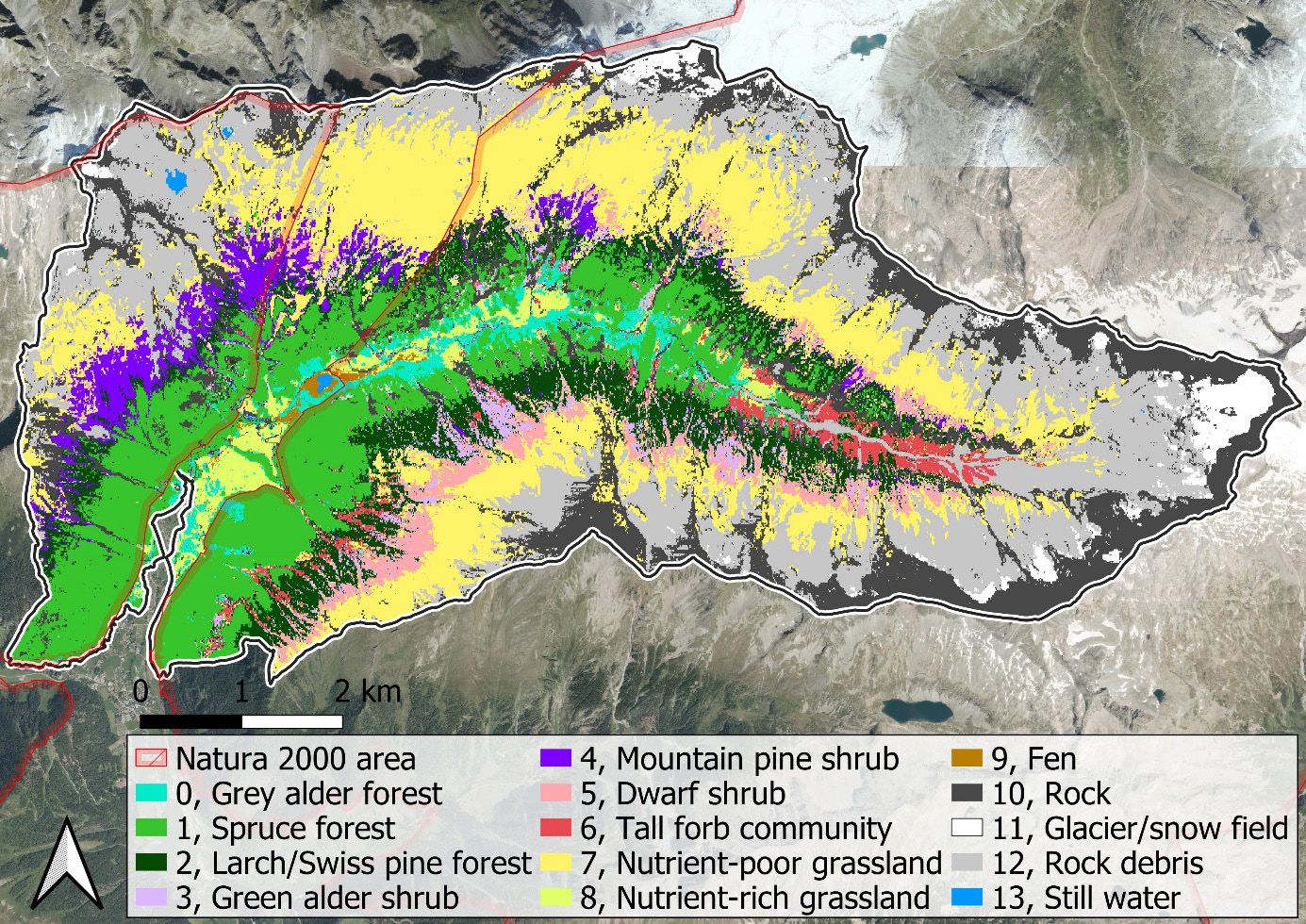
To further develop the application possibilities, I was involved in a research project with Gregory Egger, which aimed to carry out a semi-automatic area-wide classification in a mountain valley in the Hohe Tauern National Park based on Sentinel-2 satellite data. My task was the technical part of the method development and the implementation in Google Earth Engine.
In short, an algorithm was fed with locations whose biotope type was known. At these locations, the satellite images were analyzed using Machine Learning. The characteristics of the different biotope types learned in this way were then applied to each location in the study area in order to determine the most likely biotope type.
The following is a summary of the paper published in Carinthia II Part 3 – Nature Tech 2024.
Global and accelerating loss of biodiversity requires stronger management and protection of ecological resources. In Europe, various habitat types frequently need to be monitored within the framework of the Natura 2000 program. To achieve this, a robust monitoring tool, generating precise habitat maps, is crucial. Because of the specific conditions in mountainous areas, such as steep slopes and hard-to-reach areas that impede large-scale field surveys, remote sensing approaches are increasingly used to generate reliable maps. The novel classification method Google4Habitat, developed in this study, combines globally available satellite data (Sentinel/Landsat) with a series of site characteristics and upstream expert rules. Within Google Earth Engine, habitats are classified via spatial and temporal analysis based on spectral profiles and combined with factors such as elevation, vegetation height, surface roughness (based on LiDAR (light detection and ranging) data), geology, and indices for vegetation greenness (NDVI, normalized difference vegetation index), snow cover (NDSI, normalized difference snow index), and water (NDWI, normalized difference water index) in a supervised classification approach. The following questions were addressed: 1) Do the results meet the stringent habitat classification guidelines of the Red List and the requirements of Natura 2000? 2) What impact do the different qualities of input data have on the accuracy of the results? 3) Is this method suitable for capturing long-term changes in habitat distribution? We tested our model in Seebachtal, an alpine region that includes all habitat types from the montane to the nival zone and is one of the most untouched valleys in the Hohe Tauern National Park. The results are promising both in terms of habitat classification and delineation, largely meeting with the Natura 2000 guidelines. Due to their lower spatial resolution, Landsat data cannot fully detect small-area habitat types such as fens and still water. However, a comparison with the higher-resolution Sentinel-2 data shows that, in consideration of the entire study area, the classification accuracy using Sentinel-2 data did not significantly improve. Changes in habitat distribution over a 30-year-period were captured reliably. Overall, our model allows the rapid classification of large areas with high accuracy, opening new avenues for practical environmental management.